

E-A-T không chỉ là một thuật ngữ mới mà là một khái niệm tổng quát mô tả khả năng của một trang web để cung cấp thông tin chính xác, đáng tin cậy v&...

Khám phá cách tạo chiến lược Social media hiệu quả để tăng cường thương hiệu, tương tác với khách hàng và đạt được mục tiêu kinh doanh. Tận dụng các chiến thuật...

Khám phá bí quyết thành công với chiến lược nội dung thông minh và hấp dẫn. Đừng bỏ lỡ!

Nội dung chất lượng là một yếu tố quan trọng trong việc xây dựng một chiến lược tiếp thị kết hợp với SEO. Nó giúp tăng khả năng thu h...

Bounce rate - một chỉ số đánh giá hiệu quả của trang web của bạn. Nó cho biết tỷ lệ người truy cập chỉ xem một trang trên trang web của bạn trước khi rời đi. Cải thiện tỷ lệ này sẽ gi&uacu...

Chắc có lẽ Bạn đã từng nghe đến file Robots.txt là một bảng lệnh chỉ dẫn các bot công cụ tìm kiếm nên thu thập dữ liệu ở đâu. Được phép hoặc không được phép truy cập vào những file, thư mục quan trọng hay không cần thiết. Là một phần quan trọng trong việc kiểm tra và tối ưu Technical SEO.
Vậy Robots.txt là gì và làm thế nào để tạo tệp Robots.txt cho trang web tốt cho SEO, hãy cùng tìm hiểu ngay sau đây nhé.
Tệp robots.txt là gì?
Robots.txt là một tệp văn bản mà quản trị viên web tạo ra để hướng dẫn các robot web (thường là robot công cụ tìm kiếm) cách thu thập dữ liệu các trang trên trang web của họ. Tệp robots.txt là một phần của giao thức loại trừ robot (REP), một nhóm tiêu chuẩn web quy định cách robot thu thập dữ liệu web, truy cập và lập chỉ mục nội dung cũng như phân phát nội dung đó cho người dùng. REP cũng bao gồm các chỉ thị như meta robot, cũng như các hướng dẫn trên toàn trang, thư mục con hoặc trên toàn trang web về cách các công cụ tìm kiếm xử lý các liên kết (chẳng hạn như “dofollow” hoặc “nofollow”).
Trên thực tế, tệp robots.txt cho biết liệu một số tác nhân người dùng (phần mềm thu thập thông tin web) có thể hay không thể thu thập thông tin các phần của trang web. Các hướng dẫn thu thập thông tin này được chỉ định bằng cách “không cho phép – disallow” hoặc “cho phép – allow” hành vi của một số tác nhân người dùng (hoặc tất cả).
Định dạng cơ bản:
User-agent: [user-agent name]Disallow: [URL string not to be crawled]
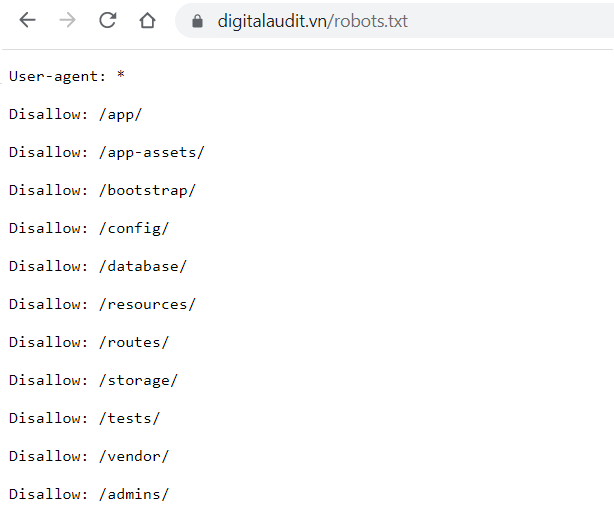
Tại sao bạn cần robots.txt?
Tệp Robots.txt kiểm soát quyền truy cập của trình thu thập thông tin vào các khu vực nhất định trên trang web của bạn. Mặc dù điều này có thể rất nguy hiểm nếu bạn vô tình không cho phép Googlebot thu thập dữ liệu toàn bộ trang web của mình (!!), nhưng có một số trường hợp mà tệp robots.txt có thể rất hữu ích.
Một số trường hợp sử dụng phổ biến bao gồm:
- Ngăn nội dung trùng lặp xuất hiện trong SERP (lưu ý rằng meta robot thường là lựa chọn tốt hơn cho việc này)
- Giữ toàn bộ các phần của trang web ở chế độ riêng tư (ví dụ: trang web dàn dựng của nhóm kỹ sư của bạn)
- Giữ cho các trang kết quả tìm kiếm nội bộ không hiển thị trên SERP công khai
- Chỉ định vị trí của (các) sơ đồ trang web
- Ngăn các công cụ tìm kiếm lập chỉ mục các tệp nhất định trên trang web của bạn (hình ảnh, PDF, v.v.)
- Chỉ định độ trễ thu thập thông tin để ngăn máy chủ của bạn bị quá tải khi trình thu thập thông tin tải nhiều phần nội dung cùng một lúc
Nếu không có khu vực nào trên trang web của bạn mà bạn muốn kiểm soát quyền truy cập của tác nhân người dùng (user-agent), bạn có thể không cần tệp robots.txt.
Robots.txt hoạt động như thế nào?
Công cụ tìm kiếm có hai công việc chính:
- Thu thập thông tin trên web để khám phá nội dung;
- Lập chỉ mục nội dung đó để nó có thể được cung cấp cho những người tìm kiếm đang tìm kiếm thông tin.
Để thu thập dữ liệu các trang web, các công cụ tìm kiếm đi theo các liên kết để đi từ trang này sang trang khác – cuối cùng là thu thập thông tin qua hàng tỷ liên kết và trang web.
Trước khi đến và xem xét một trang web, trình thu thập thông tin tìm kiếm sẽ tìm kiếm tệp robots.txt. Nếu nó tìm thấy một tệp, trình thu thập thông tin sẽ đọc tệp đó trước khi tiếp tục qua trang. Bởi vì tệp robots.txt chứa thông tin về cách công cụ tìm kiếm sẽ thu thập thông tin, thông tin tìm thấy ở đó sẽ hướng dẫn trình thu thập thông tin hành động thêm trên trang web cụ thể này. Nếu tệp robots.txt không chứa bất kỳ lệnh nào không cho phép hoạt động của tác nhân người dùng (hoặc nếu trang web không có tệp robots.txt), nó sẽ tiến hành thu thập thông tin khác trên trang web
Cách kiểm tra xem trang web có tệp robots.txt hay không?
Bạn không chắc mình có tệp robots.txt không? Chỉ cần nhập tên miền gốc của bạn, sau đó thêm /robots.txt vào cuối URL. Ví dụ: tệp robots.txt của HTH được đặt tại hthdigital.vn/robots.txt.
Nếu không có trang .txt nào xuất hiện, bạn hiện không có trang robots.txt.

Cách tạo tệp robots.txt
Tạo tệp robots.txt
Bạn có thể sử dụng hầu hết mọi trình chỉnh sửa văn bản để tạo tệp robots.txt. Ví dụ: Notepad, TextEdit, vi và emacs có thể tạo các tệp robots.txt hợp lệ. Đừng dùng trình xử lý văn bản vì trình xử lý văn bản thường lưu tệp dưới một định dạng độc quyền và có thể thêm những ký tự không mong muốn (chẳng hạn như dấu ngoặc kép); việc này có thể khiến trình thu thập dữ liệu gặp sự cố. Hãy nhớ lưu tệp bằng phương thức mã hoá UTF-8 nếu được nhắc trong hộp thoại lưu tệp.
Quy tắc về định dạng và vị trí:
- Phải đặt tên tệp là robots.txt.
- Trang web của bạn chỉ có thể có một tệp robots.txt.
- Tệp robots.txt phải nằm tại thư mục gốc trên máy chủ của trang web, tương ứng với phạm vi áp dụng của tệp. Ví dụ: để kiểm soát quá trình thu thập dữ liệu trên mọi URL tại https://www.example.com/, tệp robots.txt phải nằm tại https://www.example.com/robots.txt. Bạn không thể đặt tệp này trong một thư mục con (ví dụ như tại https://example.com/pages/robots.txt). Nếu bạn không chắc chắn về cách truy cập vào thư mục gốc của trang web hoặc cần quyền truy cập, hãy liên hệ với nhà cung cấp dịch vụ lưu trữ web. Nếu bạn không thể truy cập vào thư mục gốc của trang web, hãy dùng một phương thức chặn thay thế, chẳng hạn như thẻ meta.
- Tệp robots.txt có thể áp dụng cho các miền con (ví dụ: https://website.example.com/robots.txt) hoặc trên các cổng không chuẩn (ví dụ: http://example.com:8181/robots.txt).
- Tệp robots.txt phải là tệp văn bản được mã hoá UTF-8 (bao gồm cả ASCII). Google có thể bỏ qua các ký tự không thuộc phạm vi của UTF-8 vì các quy tắc trong tệp robots.txt có thể hiển thị không chính xác.
Thêm quy tắc vào tệp robots.txt
Các quy tắc có tác dụng hướng dẫn trình thu thập dữ liệu về những phần có thể thu thập dữ liệu trên trang web của bạn. Khi bạn thêm quy tắc vào tệp robots.txt, hãy tuân theo những nguyên tắc sau:
- Một tệp robots.txt bao gồm ít nhất một nhóm.
- Mỗi nhóm bao gồm nhiều quy tắc hoặc lệnh (hướng dẫn), mỗi lệnh nằm trên một dòng. Mỗi nhóm bắt đầu bằng một dòng User-agent nêu rõ mục tiêu của nhóm đó.
- Một nhóm cung cấp những thông tin sau:
- Đối tượng mà nhóm áp dụng (tác nhân người dùng).
- Những thư mục hoặc tệp mà tác nhân đó được phép truy cập.
- Những thư mục hoặc tệp mà tác nhân đó không được phép truy cập.
- Trình thu thập dữ liệu xử lý các nhóm từ trên xuống dưới. Một tác nhân người dùng chỉ có thể khớp với một tập hợp quy tắc – chính là nhóm đầu tiên và cụ thể nhất khớp với một tác nhân người dùng nhất định.
- Theo giả định mặc định, tác nhân người dùng có thể thu thập dữ liệu của mọi trang hoặc thư mục không bị quy tắc disallow chặn.
- Các quy tắc có phân biệt chữ hoa chữ thường. Ví dụ: disallow: /file.asp áp dụng cho https://www.example.com/file.asp nhưng không áp dụng cho https://www.example.com/FILE.asp.
- Ký tự # đánh dấu điểm bắt đầu của một nhận xét.
Trong tệp robots.txt, trình thu thập dữ liệu của Google hỗ trợ những lệnh sau:
- user-agent: [Bắt buộc, ít nhất một lệnh trong mỗi nhóm] Lệnh này chỉ định tên của ứng dụng tự động (còn được gọi là trình thu thập dữ liệu của công cụ tìm kiếm) phải tuân theo quy tắc đó. Đây là dòng đầu tiên của mọi nhóm quy tắc. Danh sách tác nhân người dùng của Google có liệt kê tên các tác nhân người dùng của Google. Dấu hoa thị (*) đại diện cho mọi trình thu thập dữ liệu, ngoại trừ các trình thu thập dữ liệu AdsBot (bạn phải nêu rõ tên cho loại trình thu thập dữ liệu này). Ví dụ:
#Example 1: Block only Googlebot
User-agent: Googlebot
Disallow: /
#Example 2: Block Googlebot and Adsbot
User-agent: Googlebot
User-agent: AdsBot-Google
Disallow: /
#Example 3: Block all but AdsBot crawlers
User-agent: *
Disallow: /
- disallow: [Ít nhất một mục disallow hoặc allow trên mỗi quy tắc] Một thư mục hoặc trang (tương đối so với miền gốc) mà bạn không muốn tác nhân người dùng thu thập dữ liệu trên đó. Nếu quy tắc đề cập đến một trang, thì trang đó phải có tên đầy đủ (như tên xuất hiện trong trình duyệt). Quy tắc này phải bắt đầu bằng một ký tự / và nếu quy tắc này đề cập đến một thư mục, thì thư mục đó phải kết thúc bằng một dấu /.
- allow: [Ít nhất một mục disallow hoặc allow trên mỗi quy tắc] Một thư mục hoặc trang (tương đối so với miền gốc) mà tác nhân người dùng đã chỉ định được phép thu thập dữ liệu trên đó. Lệnh này được dùng để ghi đè lệnh disallow nhằm cho phép thu thập dữ liệu trên một thư mục con hoặc một trang trong một thư mục không được phép. Đối với một trang đơn lẻ, hãy chỉ định tên trang đầy đủ như tên xuất hiện trong trình duyệt. Đối với một thư mục, quy tắc phải kết thúc bằng một dấu /.
- sitemap: [Không bắt buộc, có hoặc không có trong mỗi tệp] Vị trí của sơ đồ trang web cho trang web này. URL sơ đồ trang web phải là một URL đủ điều kiện; Google không giả định hoặc kiểm tra các phiên bản thay thế (http/https/www/không có www). Sơ đồ trang web là một cách hay để chỉ định nội dung mà Google nên thu thập dữ liệu, chứ không phải nội dung mà Google được phép hoặc không được phép thu thập dữ liệu. Tìm hiểu thêm về sơ đồ trang web. Ví dụ:
Sitemap: https://example.com/sitemap.xml
Sitemap: http://www.example.com/sitemap.xml
Mọi lệnh (ngoại trừ sitemap) hỗ trợ ký tự đại diện * cho một tiền tố, hậu tố hoặc toàn bộ chuỗi đường dẫn.
Các dòng không khớp với lệnh nào trong những lệnh này sẽ bị bỏ qua.
Kết luận
Bằng cách thiết lập tệp robots.txt của bạn đúng cách, bạn không chỉ nâng cao SEO của riêng mình. Bạn cũng đang giúp đỡ khách truy cập của mình.
Nếu các bot của công cụ tìm kiếm có thể chi tiêu ngân sách thu thập thông tin một cách khôn ngoan, chúng sẽ tổ chức và hiển thị nội dung của bạn trong SERPs theo cách tốt nhất, có nghĩa là bạn sẽ được hiển thị nhiều hơn.
Bạn cũng không cần phải tốn nhiều công sức để thiết lập tệp robots.txt của mình. Đây chủ yếu là thiết lập một lần và bạn có thể thực hiện một số thay đổi nhỏ nếu cần.
Cho dù bạn đang bắt đầu trang web đầu tiên hay là bao nhiêu đi nữa, việc sử dụng robots.txt có thể tạo ra sự khác biệt đáng kể. Hãy thử nếu bạn chưa từng làm trước đây và đánh giá hiệu quả nhé.
Liên hệ ngay với chúng tôi để nhận thêm tư vấn.



