

E-A-T không chỉ là một thuật ngữ mới mà là một khái niệm tổng quát mô tả khả năng của một trang web để cung cấp thông tin chính xác, đáng tin cậy v&...

Khám phá cách tạo chiến lược Social media hiệu quả để tăng cường thương hiệu, tương tác với khách hàng và đạt được mục tiêu kinh doanh. Tận dụng các chiến thuật...

Khám phá bí quyết thành công với chiến lược nội dung thông minh và hấp dẫn. Đừng bỏ lỡ!

Nội dung chất lượng là một yếu tố quan trọng trong việc xây dựng một chiến lược tiếp thị kết hợp với SEO. Nó giúp tăng khả năng thu h...

Bounce rate - một chỉ số đánh giá hiệu quả của trang web của bạn. Nó cho biết tỷ lệ người truy cập chỉ xem một trang trên trang web của bạn trước khi rời đi. Cải thiện tỷ lệ này sẽ gi&uacu...

Duplicate content (Nội dung trùng lặp) là một nỗi lo lắng thường xuyên đối với nhiều chủ sở hữu trang web. Nếu như đọc hầu hết mọi thứ về nó, bạn sẽ tin rằng “Trang web của bạn là một quả bom hẹn giờ về các vấn đề nội dung trùng lặp. Hình phạt của Google chỉ còn vài ngày nữa.”
Rất may, điều này không đúng – nhưng nội dung trùng lặp vẫn có thể gây ra các vấn đề về SEO. Và với 25 – 30% trang web là nội dung trùng lặp, bạn nên nghĩ đến cách tránh và khắc phục vấn đề này.
Duplicate content là gì?
Duplicate content-Nội dung trùng lặp là những khối nội dung lớn trên một hoặc nhiều miền, hoàn toàn trùng khớp hoặc rất giống với nội dung khác trong cùng một ngôn ngữ. - Theo Google định nghĩa.
Tại sao duplicate content lại quan trọng?
Đối với công cụ tìm kiếm
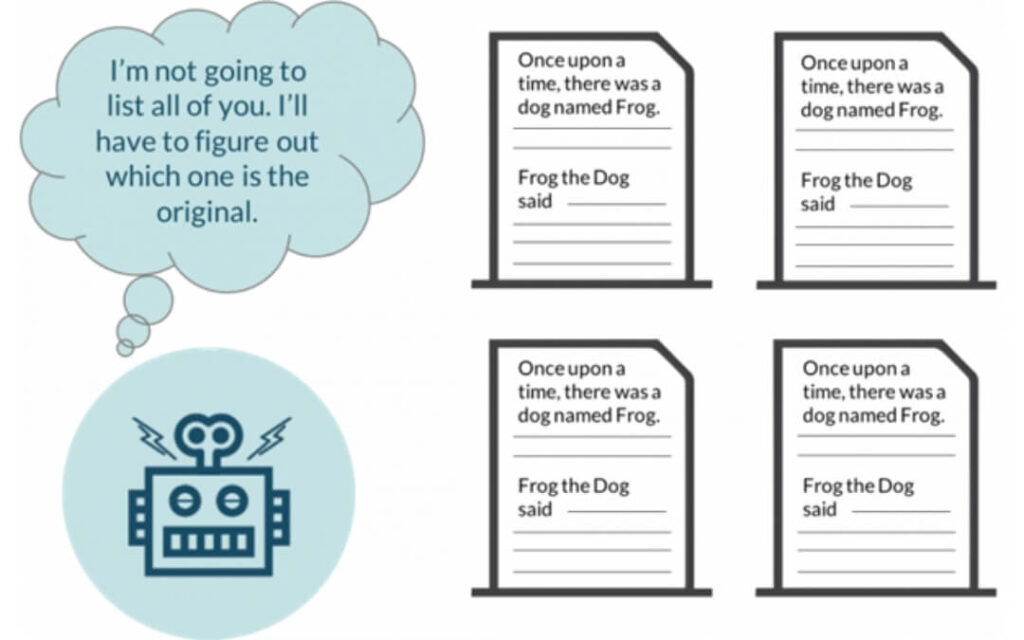
Duplicate content có thể gây ra ba vấn đề chính đối với các công cụ tìm kiếm:
- Công cụ không biết nên bao gồm/ loại trừ (các) phiên bản nào khỏi chỉ số của mình.
- Không biết có nên định hướng các chỉ số liên kết (độ tin cậy, quyền hạn, văn bản liên kết, liên kết vốn chủ sở hữu, v.v.) với một trang hoặc giữ nó tách biệt giữa nhiều phiên bản.
- Công cụ không biết (các) phiên bản nào để xếp hạng cho các kết quả truy vấn.
Đối với chủ sở hữu trang web
Khi duplicate content xuất hiện, chủ sở hữu trang web có thể bị mất thứ hạng và lưu lượng truy cập. Những tổn thất này thường xuất phát từ hai vấn đề chính:
- Để cung cấp trải nghiệm tìm kiếm tốt nhất, các công cụ tìm kiếm sẽ hiếm khi hiển thị nhiều phiên bản của cùng một nội dung và do đó buộc phải chọn phiên bản nào có nhiều khả năng mang lại kết quả tốt nhất. Điều này làm loãng khả năng hiển thị của từng bản sao.
- Giá trị liên kết có thể bị pha loãng hơn nữa vì các trang web khác cũng phải lựa chọn giữa các bản sao. thay vì tất cả các liên kết đến đều trỏ đến một phần nội dung, chúng liên kết đến nhiều phần, làm lan tỏa liên kết giữa các phần trùng lặp. Bởi vì các liên kết trong nước là một yếu tố xếp hạng , điều này sau đó có thể ảnh hưởng đến khả năng hiển thị tìm kiếm của một phần nội dung.
Tại sao lại xảy ra các vấn đề về nội dung trùng lặp?
Trong phần lớn các trường hợp, chủ sở hữu trang web không cố ý tạo nội dung trùng lặp. Nhưng, điều đó không có nghĩa là nó không nằm ngoài đó. Trên thực tế, theo một số ước tính, có tới 29% trang web thực sự là nội dung trùng lặp!
Hãy cùng xem xét một số cách phổ biến nhất mà nội dung trùng lặp được tạo ra do vô tình:
1. Các biến thể URL
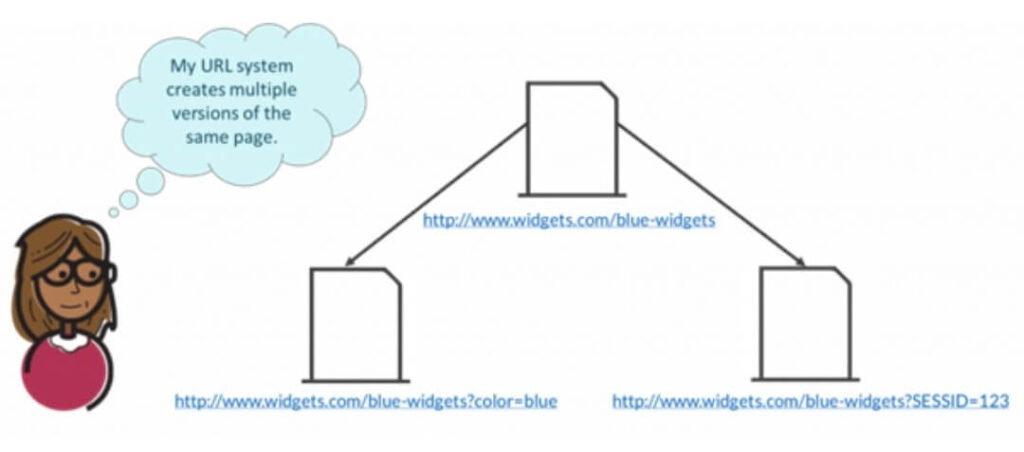
Các thông số URL, chẳng hạn như theo dõi lần nhấp và một số mã phân tích, có thể gây ra các vấn đề về nội dung trùng lặp. Đây có thể là sự cố không chỉ do chính các tham số gây ra mà còn do thứ tự mà các tham số đó xuất hiện trong chính URL.
Ví dụ:
www.widgets.com/blue-widgets?c … là bản sao của www.widgets.com/blue-widgets?c … & cat = 3 “class =” redactor-autoparser-object “> www.widgets. com / blue-widgets là một bản sao của www.widgets.com/blue-widgets ? cat = 3 & color = blue
Tương tự, ID phiên là một trình tạo nội dung trùng lặp phổ biến. Điều này xảy ra khi mỗi người dùng truy cập một trang web được chỉ định một ID phiên khác được lưu trữ trong URL.
Các phiên bản nội dung thân thiện với máy in cũng có thể gây ra các vấn đề về nội dung trùng lặp khi nhiều phiên bản của trang được lập chỉ mục.
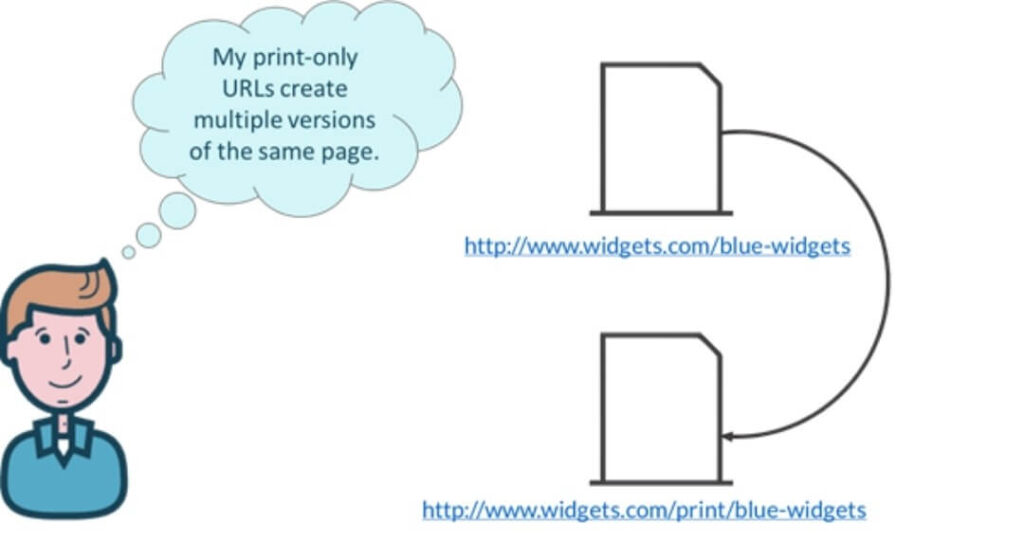
Một bài học ở đây là khi có thể, bạn thường tránh thêm các tham số URL hoặc các phiên bản thay thế của URL (thông tin chứa các URL đó thường có thể được chuyển qua các tập lệnh).
2. Các trang HTTP so với HTTPS hoặc WWW so với không phải WWW
Nếu trang web của bạn có các phiên bản riêng biệt tại “www.site.com” và “site.com” (có và không có tiền tố “www”) và nội dung giống nhau ở cả hai phiên bản, thì bạn đã tạo một cách hiệu quả các bản sao của từng phiên bản đó các trang. Điều tương tự cũng áp dụng cho các trang web duy trì phiên bản tại cả http:// và https://. Nếu cả hai phiên bản của một trang đều hiển thị trực tiếp và hiển thị cho các công cụ tìm kiếm, bạn có thể gặp phải vấn đề nội dung trùng lặp.
3. Nội dung cóp nhặt hoặc sao chép
Nội dung không chỉ bao gồm các bài đăng trên blog hoặc nội dung biên tập mà còn bao gồm các trang thông tin về sản phẩm. Scrapers xuất bản lại nội dung blog của bạn trên các trang web của chính họ có thể là một nguồn nội dung trùng lặp quen thuộc hơn, nhưng cũng có một vấn đề phổ biến đối với các trang web thương mại điện tử: thông tin sản phẩm. Nếu nhiều trang web khác nhau bán các mặt hàng giống nhau và tất cả đều sử dụng mô tả của nhà sản xuất về các mặt hàng đó, thì nội dung giống hệt nhau sẽ xuất hiện ở nhiều vị trí trên web.
Cách khắc phục sự cố Duplicate content
Việc khắc phục các vấn đề về nội dung trùng lặp đều có chung một ý tưởng chính: chỉ định nội dung trùng lặp nào là “đúng”.
Bất cứ khi nào nội dung trên một trang web có thể được tìm thấy ở nhiều URL, nó nên được chuẩn hóa cho các công cụ tìm kiếm. Hãy xem qua ba cách chính để thực hiện việc này: Sử dụng chuyển hướng 301 đến đúng URL, thuộc tính rel = canonical hoặc sử dụng công cụ xử lý tham số trong Google Search Console.
Chuyển hướng 301
Trong nhiều trường hợp, cách tốt nhất để chống lại nội dung trùng lặp là thiết lập chuyển hướng 301 từ trang “trùng lặp” đến trang nội dung gốc.
Khi nhiều trang có tiềm năng xếp hạng tốt được kết hợp thành một trang duy nhất, chúng không chỉ ngừng cạnh tranh với nhau; chúng cũng tạo ra một tín hiệu liên quan và phổ biến mạnh hơn về tổng thể. Điều này sẽ tác động tích cực đến khả năng xếp hạng tốt của trang “chính xác”.

Sử dụng Rel = “canonical”
Một tùy chọn khác để xử lý nội dung trùng lặp là sử dụng thuộc tính rel = canonical . Điều này cho các công cụ tìm kiếm biết rằng một trang nhất định phải được coi là bản sao của một URL được chỉ định và tất cả các liên kết, chỉ số nội dung và “sức mạnh xếp hạng” mà các công cụ tìm kiếm áp dụng cho trang này phải thực sự được ghi nhận vào URL.
Thuộc tính rel = “canonical” là một phần của phần đầu HTML của trang web và trông giống như sau:
Định dạng chung:
… [mã khác có thể có trong phần đầu HTML của tài liệu của bạn] … …[ mã khác có thể có trong tài liệu của bạn HTML head] …
Thuộc tính rel = canonical phải được thêm vào phần đầu HTML của mỗi phiên bản trùng lặp của trang, với phần “URL CỦA TRANG GỐC” ở trên được thay thế bằng liên kết đến trang gốc (chuẩn). (Hãy đảm bảo rằng bạn giữ nguyên dấu ngoặc kép.) Thuộc tính chuyển gần như bằng giá trị liên kết (sức mạnh xếp hạng) như chuyển hướng 301 và bởi vì nó được triển khai ở cấp trang (thay vì máy chủ), thường mất ít thời gian phát triển hơn để thực hiện.
Meta Robots Noindex
Một thẻ meta có thể đặc biệt hữu ích trong việc xử lý nội dung trùng lặp là meta robot , khi được sử dụng với các giá trị “noindex, follow”. Thường được gọi là Meta Noindex, Follow và được biết đến về mặt kỹ thuật là content = “noindex, follow”, thẻ meta robot này có thể được thêm vào phần đầu HTML của mỗi trang riêng lẻ cần được loại trừ khỏi chỉ mục của công cụ tìm kiếm.
Định dạng chung:
… [mã khác có thể nằm trong phần đầu HTML của tài liệu của bạn] … … [mã khác có thể nằm trong phần đầu HTML của tài liệu của bạn ] …
Thẻ meta robot cho phép các công cụ tìm kiếm thu thập thông tin các liên kết trên một trang nhưng không cho chúng bao gồm các liên kết đó trong chỉ mục của chúng. Điều quan trọng là trang trùng lặp vẫn có thể được thu thập thông tin, ngay cả khi bạn đang yêu cầu Google không lập chỉ mục trang đó, vì Google cảnh báo rõ ràng về việc hạn chế quyền truy cập thu thập thông tin đối với nội dung trùng lặp trên trang web của bạn. (Các công cụ tìm kiếm muốn có thể xem mọi thứ trong trường hợp bạn đã mắc lỗi trong mã của mình. Nó cho phép chúng thực hiện “lệnh gọi phán xét” [có khả năng tự động] trong các tình huống không rõ ràng.)
Sử dụng meta rô bốt là một giải pháp đặc biệt tốt cho các vấn đề trùng lặp nội dung liên quan đến phân trang.
Tên miền ưa thích và xử lý tham số trong Google Search Console
Google Search Console cho phép bạn đặt tên miền ưa thích của trang web của mình (tức là http://yoursite.com thay vì http://www.yoursite.com) và chỉ định liệu Googlebot có nên thu thập thông tin các tham số URL khác nhau hay không (xử lý tham số).
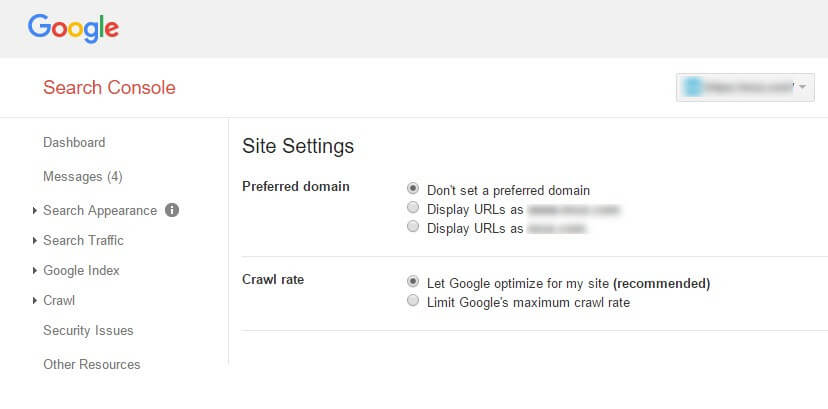
Tùy thuộc vào cấu trúc URL của bạn và nguyên nhân của các vấn đề nội dung trùng lặp, việc thiết lập miền hoặc xử lý thông số ưa thích của bạn (hoặc cả hai!) Có thể cung cấp giải pháp.
Hạn chế chính của việc sử dụng xử lý tham số làm phương pháp chính để xử lý nội dung trùng lặp là những thay đổi bạn thực hiện chỉ có tác dụng với Google. Bất kỳ quy tắc nào được áp dụng bằng Google Search Console sẽ không ảnh hưởng đến cách Bing hoặc bất kỳ trình thu thập thông tin của công cụ tìm kiếm nào khác diễn giải trang web của bạn; bạn sẽ cần sử dụng các công cụ quản trị trang web cho các công cụ tìm kiếm khác ngoài việc điều chỉnh cài đặt trong Search Console.
Các phương pháp bổ sung để xử lý nội dung trùng lặp
- Duy trì tính nhất quán khi liên kết nội bộ trên toàn bộ trang web. Ví dụ: nếu quản trị viên web xác định rằng phiên bản chuẩn của miền là www.example.com/, thì tất cả các liên kết nội bộ sẽ chuyển đến http://www.example.co … chứ không phải http://example.com/pa … (lưu ý sự vắng mặt của www).
- Khi cung cấp nội dung, hãy đảm bảo rằng trang web cung cấp thêm liên kết quay lại nội dung ban đầu và không phải là một biến thể trên URL.
- Để thêm một biện pháp bảo vệ chống lại những kẻ phá nội dung ăn cắp tín dụng SEO cho nội dung của bạn, bạn nên thêm một liên kết rel = canonical tự tham chiếu vào các trang hiện có của mình. Đây là một thuộc tính kinh điển trỏ đến URL mà nó đã có, mục đích là để ngăn cản nỗ lực của một số người cóp nhặt.
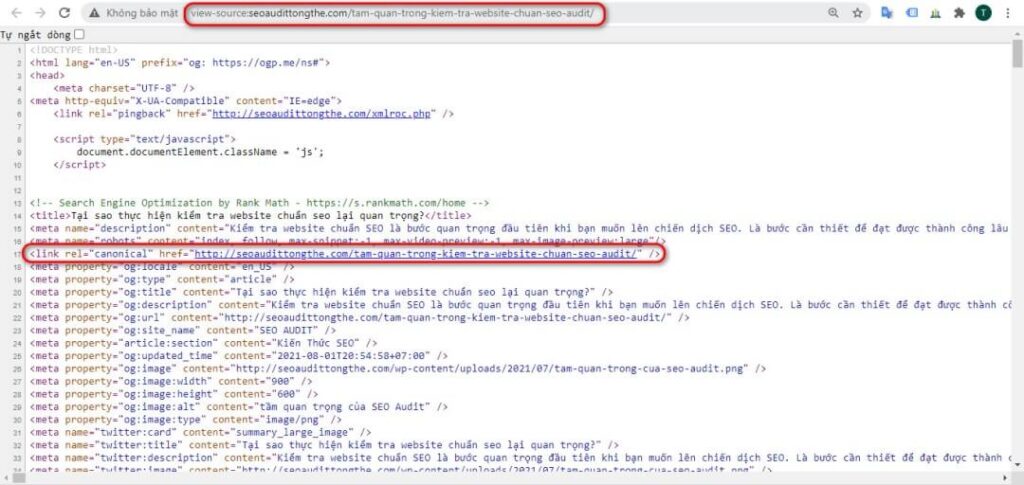
Liên kết rel = canonical tự tham chiếu: URL được chỉ định trong thẻ rel = canonical giống với URL trang hiện tại.
Mặc dù không phải tất cả các công cụ tìm kiếm sẽ chuyển qua mã HTML đầy đủ của tài liệu nguồn của họ, nhưng một số sẽ làm như vậy. Đối với những điều đó, thẻ rel = canonical tự tham chiếu sẽ đảm bảo phiên bản trang web của bạn được ghi nhận là phần nội dung “gốc”.
Hy vọng qua bài viết này, bạn đã hiểu hơn đề duplicate content cũng như nắm được cách khắc phục nó như thể nào. Ngoài ra, để đảm bảo rằng các nội dung của bạn đăng lên không bị trùng lặp, hãy sử dụng các công cụ kiểm tra trùng lặp online để xác định nhé.
Liên hệ ngay với chúng tôi để nhận thêm tư vấn.



